MapReduce API
To load data into its Accumulo tables, DataWave provides an API that utilizes MapReduce as its basis. This framework is highly scalable and is designed to support extensive customization through configuration alone. For example, DataWave can be configured to ingest arbitrarily-defined data schemas with no software development required, provided that the ingested schemas are encoded in common file formats such as CSV, JSON, etc.
DataWave Ingest can also be extended to accept new file formats with minimal software development. Typically, this is accomplished by extending one or more base classes within the API and by implementing familiar Hadoop MapReduce abstractions such as InputFormat and RecordReader.
Within this framework, distributed map tasks perform the work of transforming your raw data objects into Accumulo key/value pairs. These are created in accordance with the DataWave data model and as prescribed by any user-supplied configuration.
Data Flow Overview
Raw data will often require grooming or pre-processing of some sort before being passed along to DataWave to be ingested. However, this happens outside of the scope and purview of DataWave. Thus, DataWave’s interaction with incoming data begins in HDFS.
Each distinct data type registered within DataWave Ingest will have a configured “base directory” within HDFS, where a dedicated Flag Maker process will monitor the arrival of new files for the given type. Based on the Flag Maker’s governing configuration, it will group some number of these files together and mark them as “flagged”, which signals that they are ready to be submitted as input to a MapReduce job.
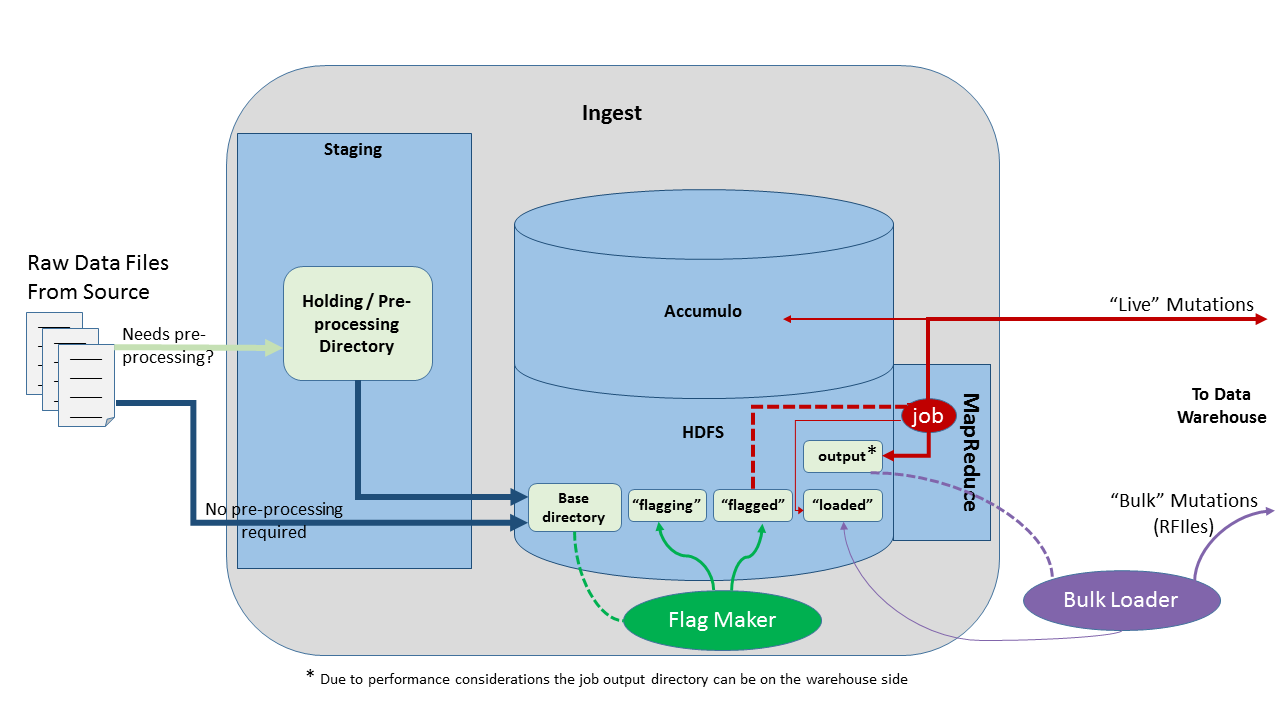
Live Ingest
A DataWave ingest job configured to operate in live mode is a map-only job in which the mappers use Accumulo BatchWriter instances to write data directly into Tablet Server memory and into DataWave’s tables. Thus, live mode provides the least amount of ingest latency from the user’s perspective, because the new data is made available for query immediately without first having to write it to disk.
However, Accumulo must eventually write out the data to the distributed file system. For clusters that must support continuous data ingest while concurrently servicing user queries, live ingest may result in significantly degraded performance overall, because ingest- and query-related activities within Accumulo may often be forced to compete with one another for the same CPU, memory, and network resources.
Bulk Ingest
In contrast, DataWave ingest jobs configured to operate in bulk mode use the reduce phase to write pre-sorted key/value pairs as RFiles, Accumulo’s native file format, directly to the distributed file system. DataWave’s Bulk Loader is then employed to manage the bulk import into Accumulo, which can bring a large volume of RFiles online all at once and requiring very little overhead on the part of Tablet Servers.
This may allow for greater overall ingest throughput and also give priority to user queries in terms of resource consumption, particularly when leveraging dedicated ingest nodes that are physically segregated from the primary Accumulo cluster. Therefore, the tradeoff here is the potential for increased latency, in terms of the time that it takes for the most recent data to be made available for query.